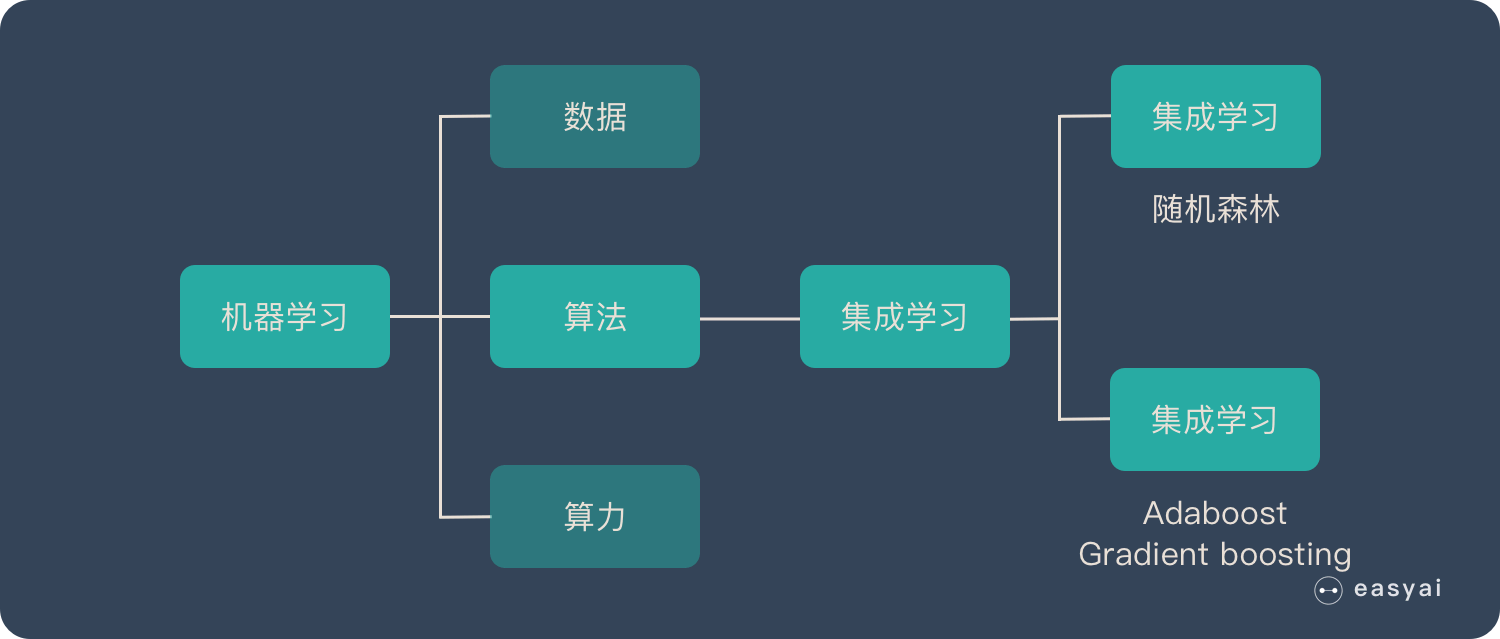
最大匹配算法
(贪心算法)
例子:经常有意见分歧
词典:[‘有’, ‘意见’,‘有意见’, ‘分歧’, ‘经常’]
超参数:max_length = 5
前向最大匹配算法
… [经常有意见] 分歧 —- 不在词典
… [经常有意] 见分歧 —- 不在词典
…
… [经常] 有意见分歧 —- 在词典 —- 经常提出来 —- 句子: 有意见分歧
… 经常|有意见|分歧
后向最大匹配算法
… 经常 [有意见分歧] —- 不在词典
… 经常有 [意见分歧] —- 不再词典
…
… 经常 |有意见|分歧
90%的句子前向和后向都是一致的,但是有10%的句子是不一样的 —- 比如:南京市长江大桥
可以结合前向和后向组成双向最大匹配算法,一致则成立,不一致,取句子中词最少的结果 —- 符合最大匹配思想
语言模型
Uni-gram
… 输入一句话 —- ( 1 ) —-生成所有可能的分割 —- ( 2 ) —-选取其中最好的
… $p(s1)=0.3$ —- $p(经常, 有, 意见, 分歧)$ == $p(经常)·p(有)·p(意见)·p(分歧)$
… $p(s2)=0.35$ —- $p(经常, 有意见, 分歧)$ == $p(经常)·p(有意见)·p(分歧)$
…
每个词都有概率 —- 我有一个词典 —- 每次词出现的词数 / 总祠数
有Uni-gram 同理也可以用Bi-gram …
问题:
复杂度很高
疑问
当词典过大的时候 每次词的概率可能很小 —- 算出来的结果可能计算机识别不了
由乘法换成加法 —- $p(经常)·p(有)·p(意见)·p(分歧)$ —> $log(p(经常))+log(p(有))+log(p(意见))+log(P(分歧))$
Vertib 入门
将语言模型 1,2 整合在一起 优化复杂度
每条路径都是一个分词的可能
动态规划思想 —- 找到概率最小路径 —- 思想:大问题才分成若干个小问题
到达第 8 个节点 —- 三条线 —- 6-8, 7-8, 5-8
6-8 —- 1到6的路径又分为 —- 4-6,5-6,3-6
7-8 —- 1到7的路径又分为 —- 7-6
5-8 —- 1到5的路径又分为 —- 4-5
….
以此类推 —- 最优结果为 1-3-6-8